
민스씨의 일취일장
TIssue | 성능 테스트 적정 환경 찾기 (Feat. 매번 같은 양상의 메트릭 측정 됨) 본문
Github Issues #17에 대한 글입니다.
성능 테스트 - 적정 환경 찾기

이슈
nGrinder 컨트롤러와 에이전트를 연결시키고, Prometheus와 Grafana를 이용해 메트릭을 수집하고 시각화하는 것까지 잘 되었다. 그런데 이상하게 어떤 조건에서도 CPU 점유율 양상이나, 평균 반응 시간 등의 그래프가 비슷한 양상을 띄었다. 분명히 조건이 달라진다면 반응도 달라져야 하는데, 언제나 똑같았다.
문제 파악
문제를 파악하기에 앞서 테스트가 어떻게 이뤄졌었는지 살펴보도록 하겠다.
테스트 환경
서버 : AWS EC2
OS : Amazon-Linux
Database : AWS RDS
특징 : Docker Container로 구동
테스트 도구
nGrinder Controller : 로컬 PC에서 실행
nGrinder Agent : 1개의 Agent, 서비스와 동일 서버의 다른 컨테이너로 실행
흐름도
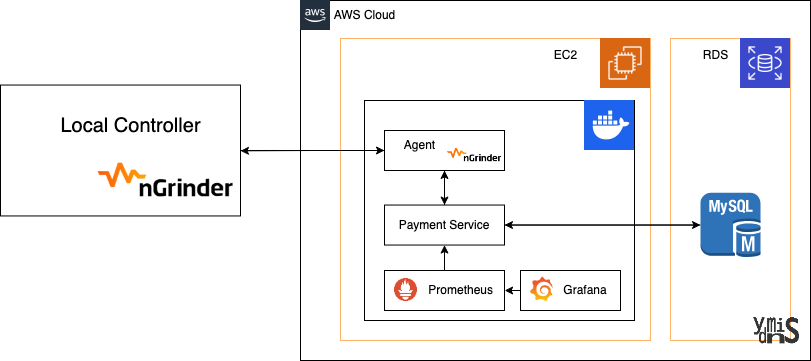
탐색
원인을 파악하기 위해서 다양한 조건으로 테스트를 진행해 보았다.
Case 1 - JVM 메모리 256mb / 컨테이너 메모리 768mb & 메모리 스왑 768mb
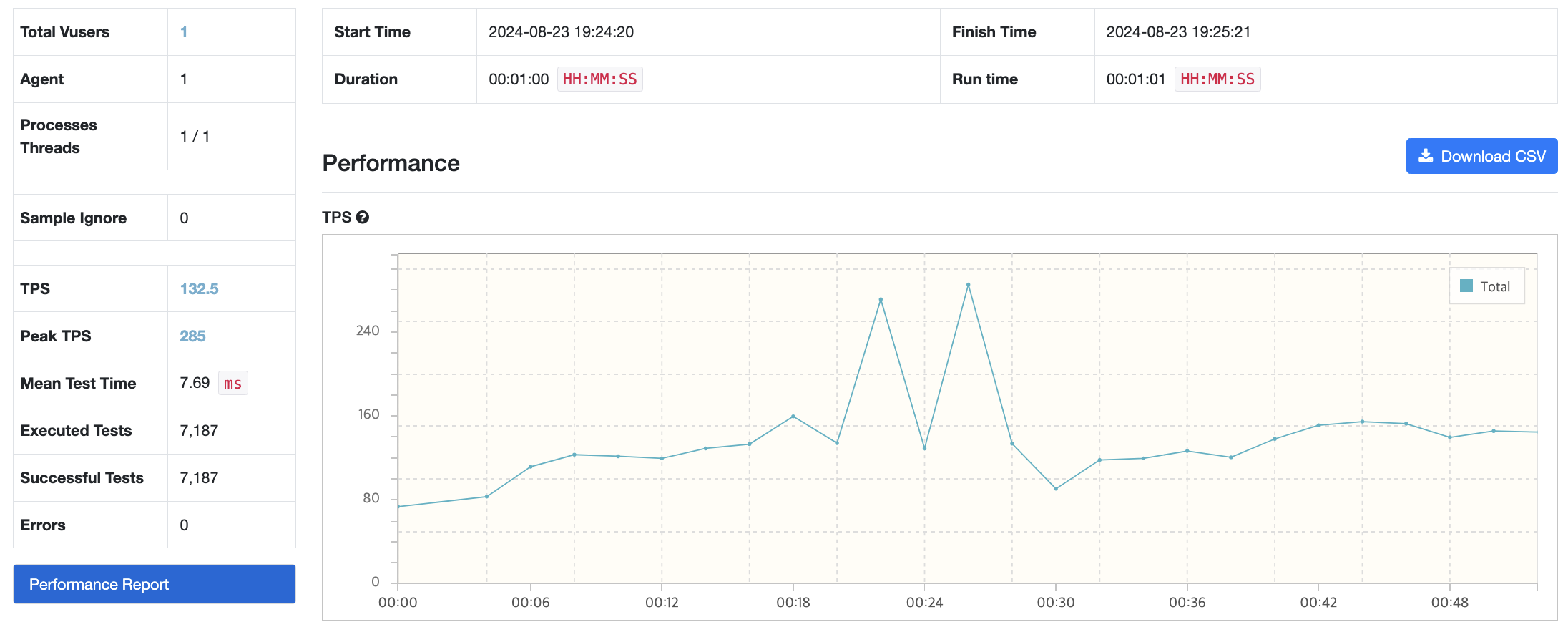



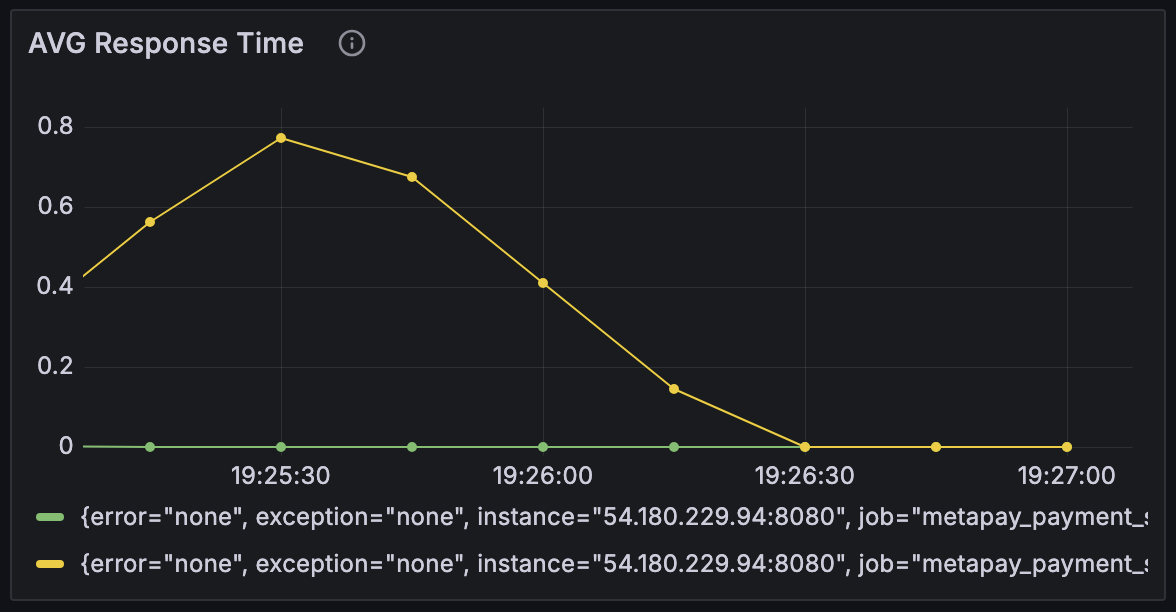
Case 2 - 메모리 스왑 2배로 : JVM 메모리 256mb / 컨테이너 메모리 768mb & 메모리 스왑 1536mb

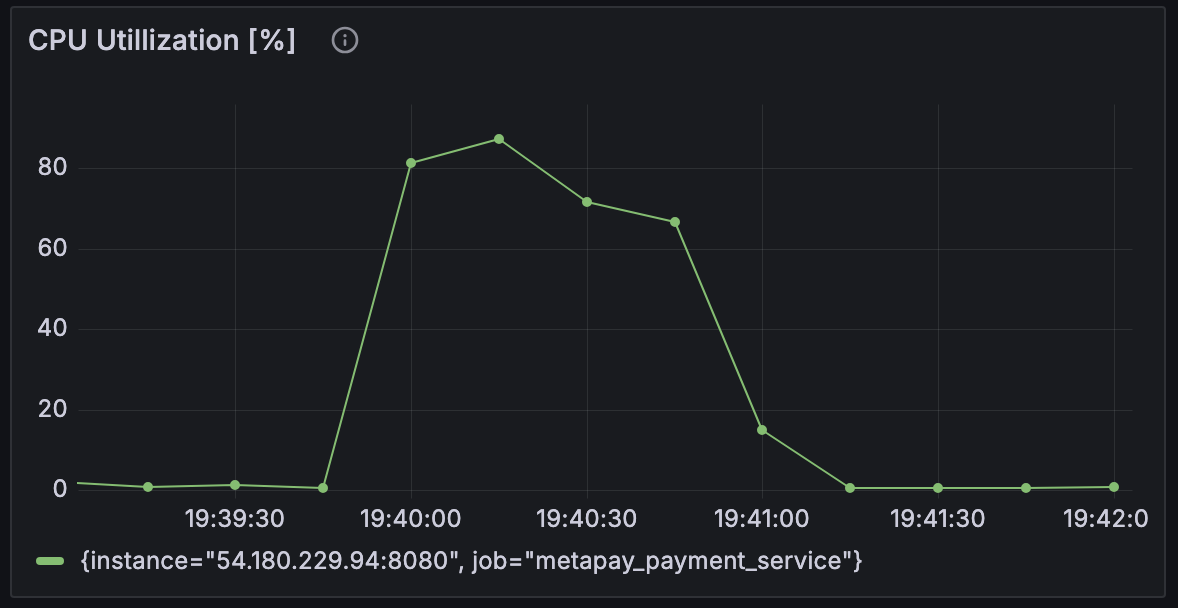


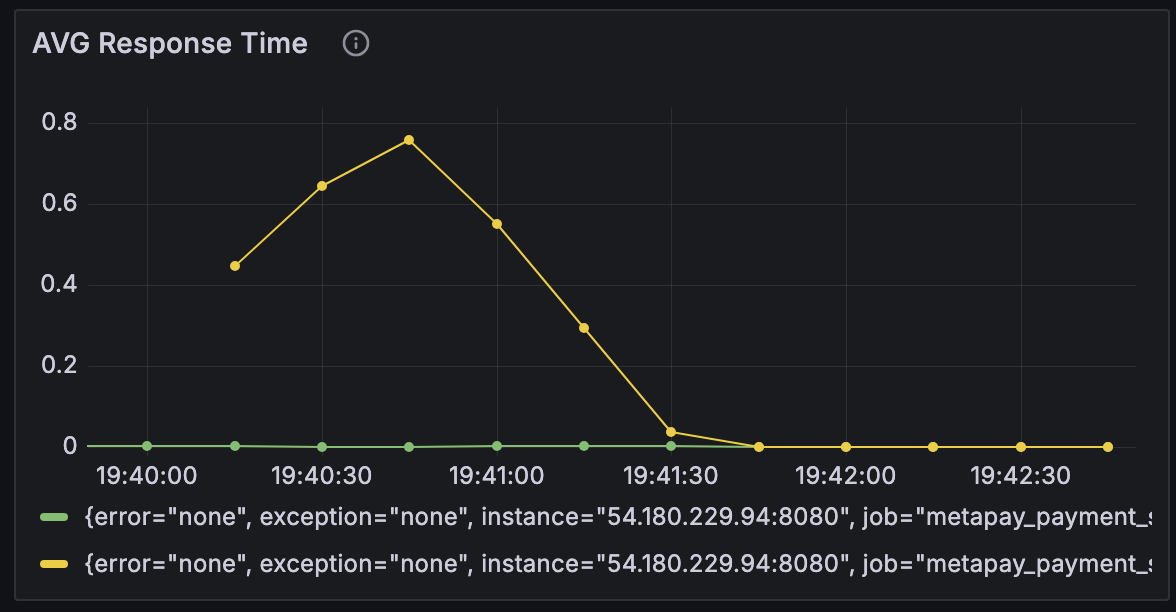
Case 3 - 컨테이너 메모리 2G, 메모리 스왑 2G로 확대 : JVM 메모리 256mb / 컨테이너 메모리 2G & 메모리 스왑 2G
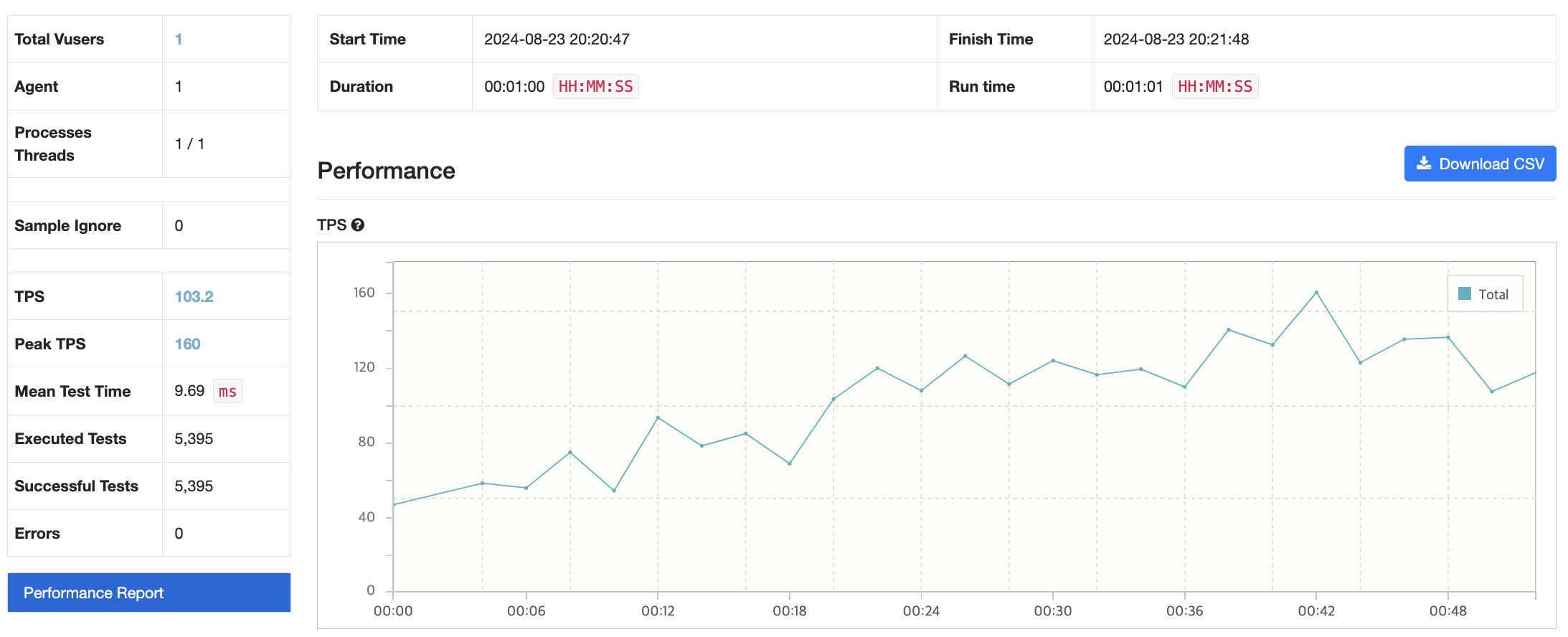


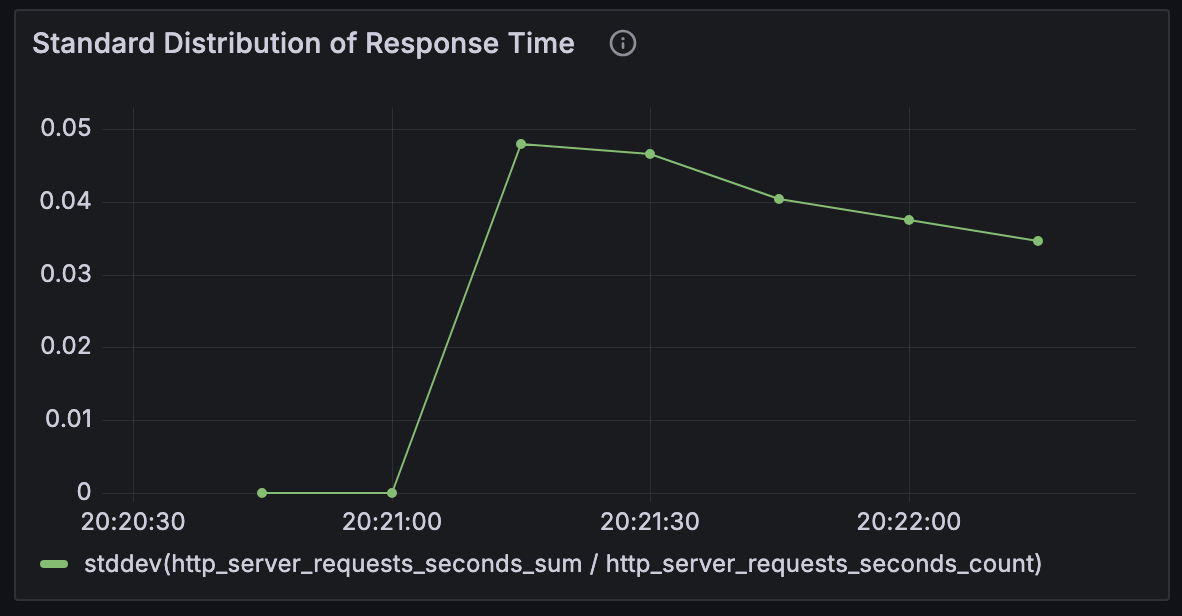

Case 4 - 메모리 스왑 2배로 : JVM 메모리 256mb / 컨테이너 메모리 2G & 메모리 스왑 4G
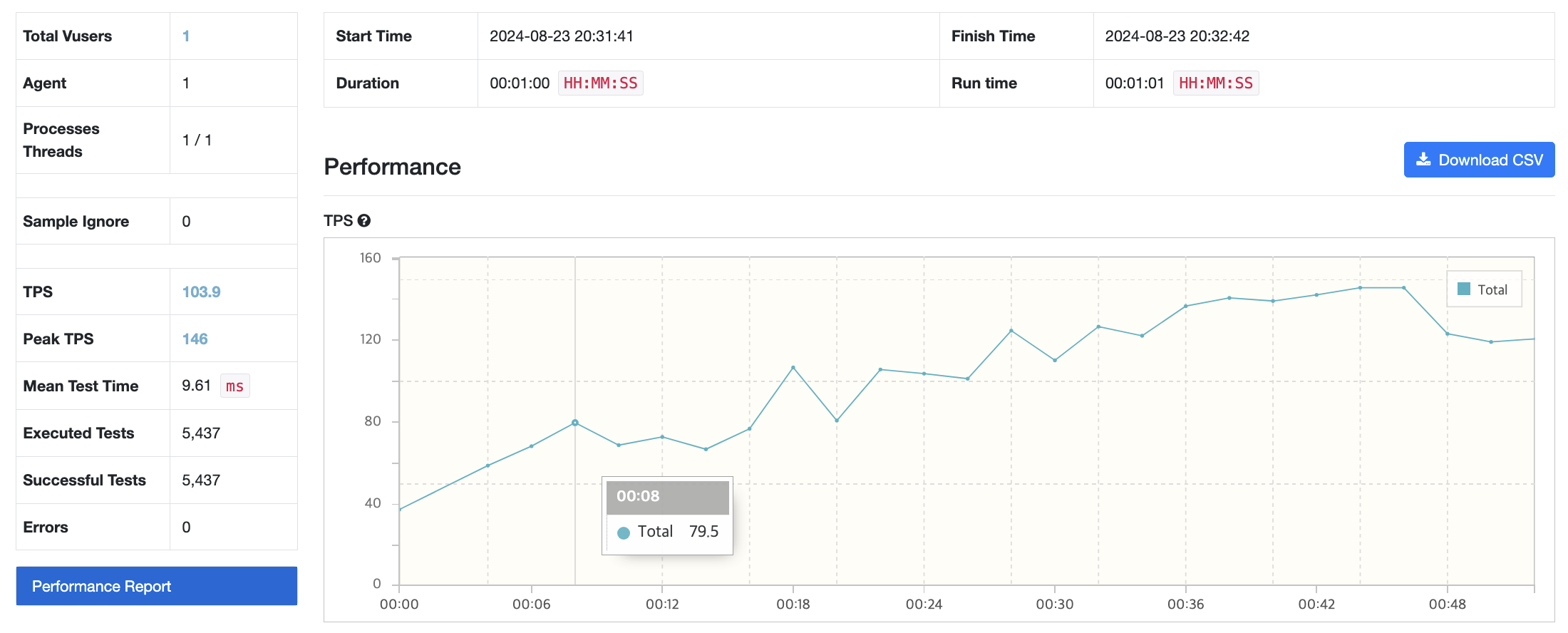
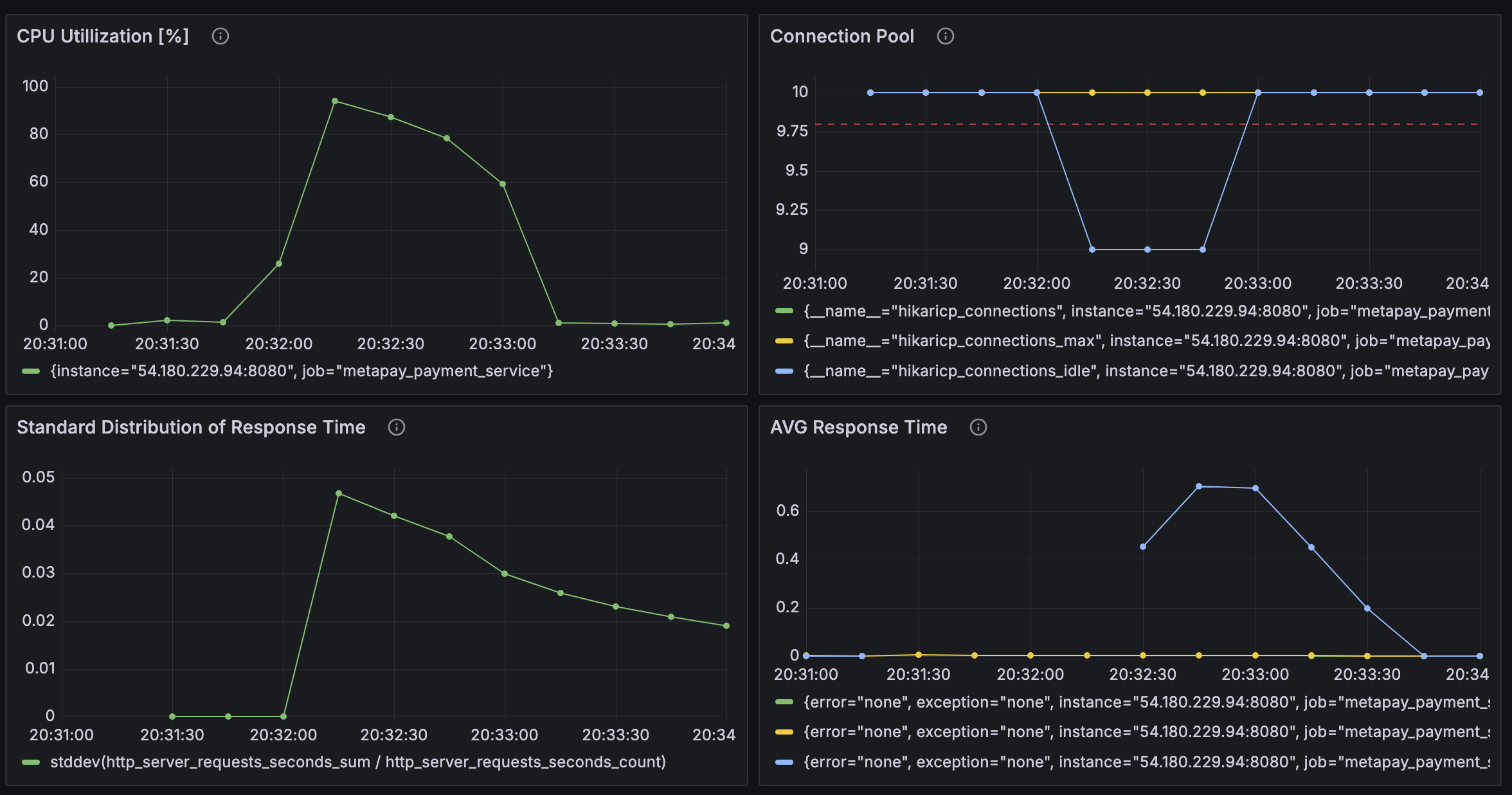
Case 5 - JVM 메모리 2배 : JVM 메모리 512mb, 컨테이너 메모리 2G, 메모리 Swap 2G


테스트 중단 후 고민
뭔가 이상함을 느꼈다. 어떤 지표를 바꿔도 그래프의 양상은 그대로이고, 가상 사용자인 Vuser는 1을 넘기기만 해도 테스트가 중단되기 일
수였다. 지금까지 수정한 수치들이 문제가 아닐 수 있음을 의심하기 시작했다. 그래서 Service가 CPU를 너무 적게 배정된 건 아닌지 살펴보았는데, 그렇지 않았다. 제한을 두지 않고 사용했기 때문에 필요하다면 가용가능한 CPU 자원을 모두 사용할 수 있었다. 그럼 EC2 free tier가 CPU가 너무 작나? 하는 생각이 들었다. 그래도 그렇지, 가상 사용자가 1명밖에 안된다는 건 말이 안됐다.
원인 파악
그렇게 고민하던 중 갑자기 Agent로 눈이 쏠리기 시작했다. Agent도 EC2 내 도커 환경에서 컨테이너로 띄워졌으며, Service와 마찬가지로 CPU 제한이 걸려있지 않았다. 그리고 Agent는 대용량 부하를 생성하기 때문에 리소스를 많이 사용하게 될 것이다. 문제는 이 곳일꺼라 생각해, 그래도 성능이 나쁘지 않은 로컬 맥분 환경으로 옮겨왔다. Controller와 같은 PC에 있다는 것이 조금 신경이 쓰였지만 그래도 의미있는 테스트는 진행할 수 있을 거라고 판단했다.
nGrinder Agent 옮기기
모든 상황을 똒같이 둔 채로, Agent만 로컬 환경으로 옮겨오고 EC2 내의 Agent는 종료시켜주었다. 그런 다음 테스트를 돌렸는데, 이전과는 완전히 다른 양상의 그래프를 나타내기 시작했다. Error가 한 번도 없었는데 Error도 발생하기 시작했다. 그런데 Error가 하나도 없는 게 이상했다. 그렇게 대용량 트래픽을 발생시키는데. 또 신기한 점은 Vuser를 10으로 늘려도 문제없이 테스트가 돌아갔다.
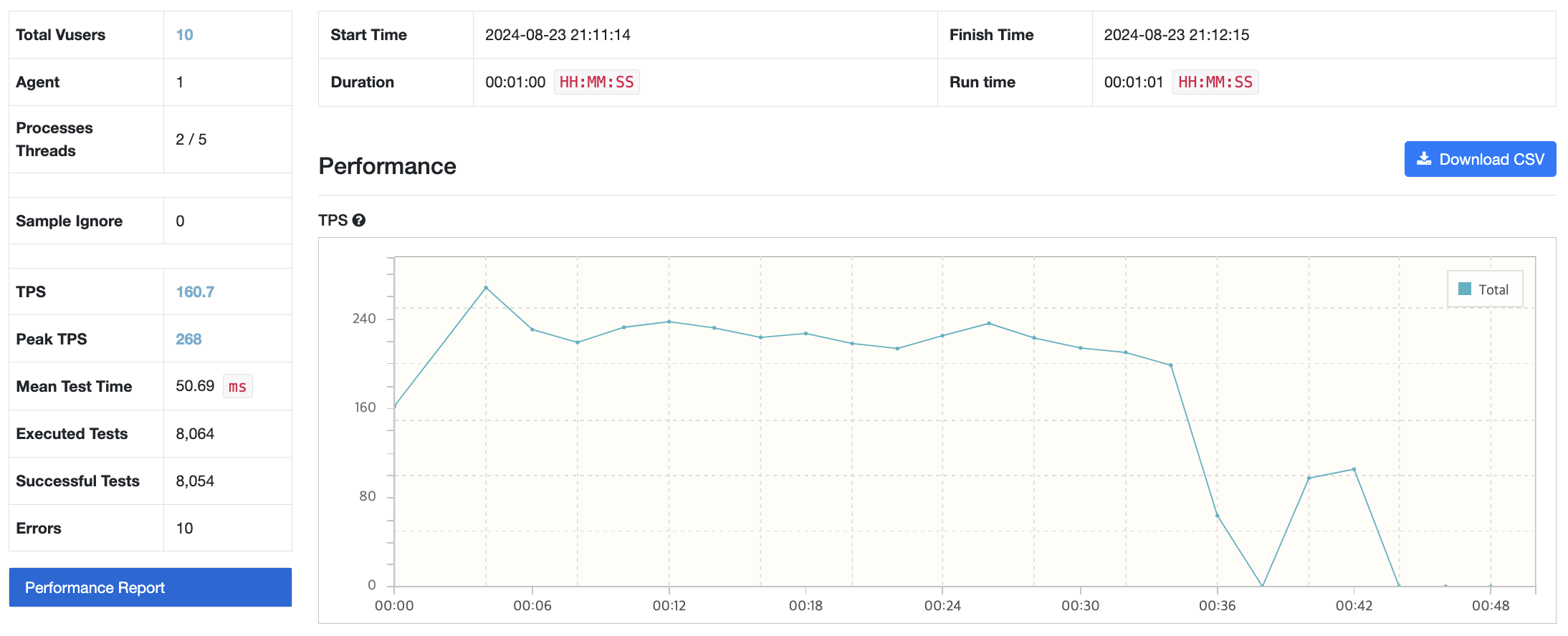
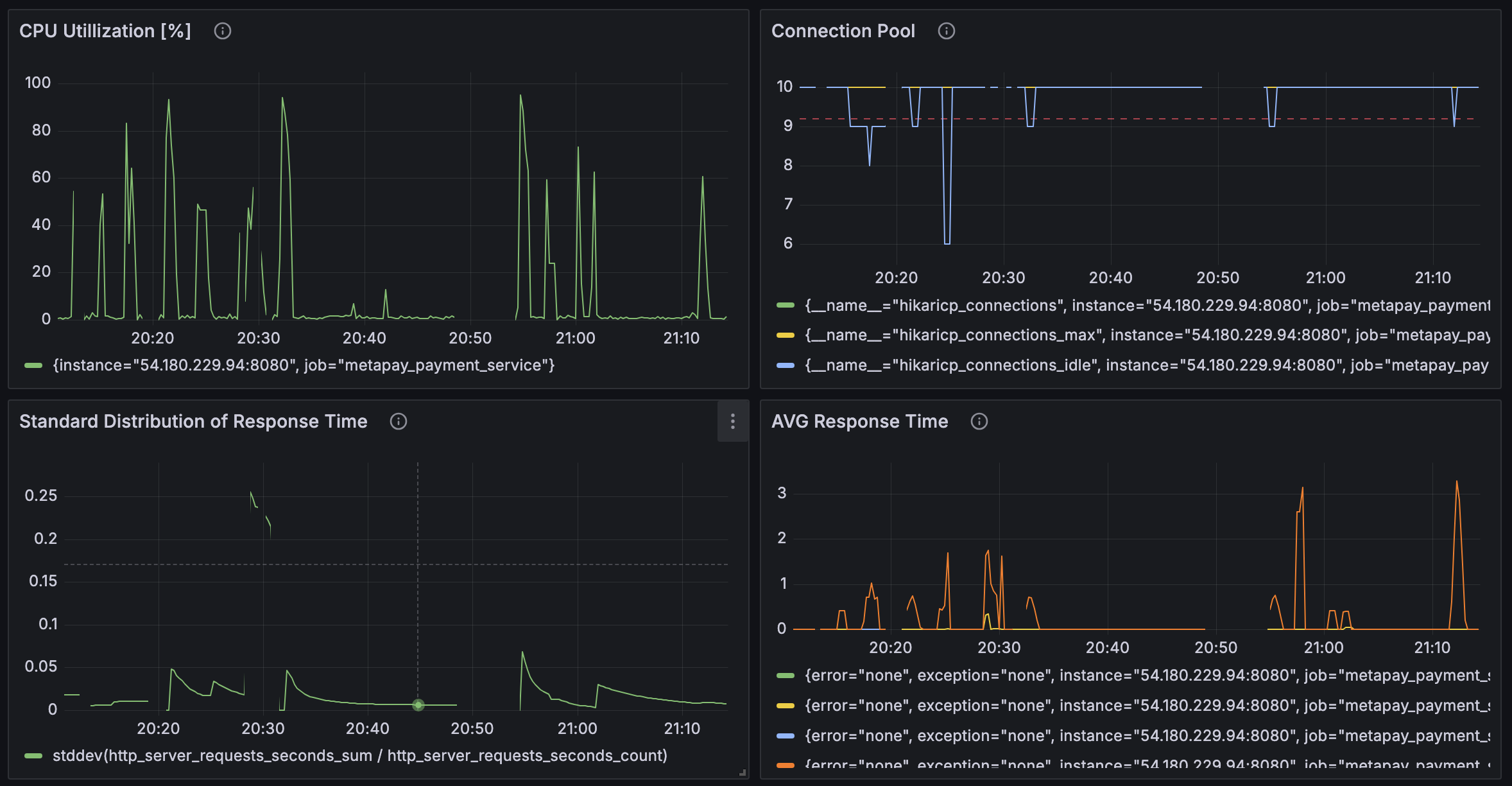
내친김에 Vuser도 100으로 설정해 보았다. (그럼 99로 자동으로 변경된다.) 100도 문제 없이 작동했다.

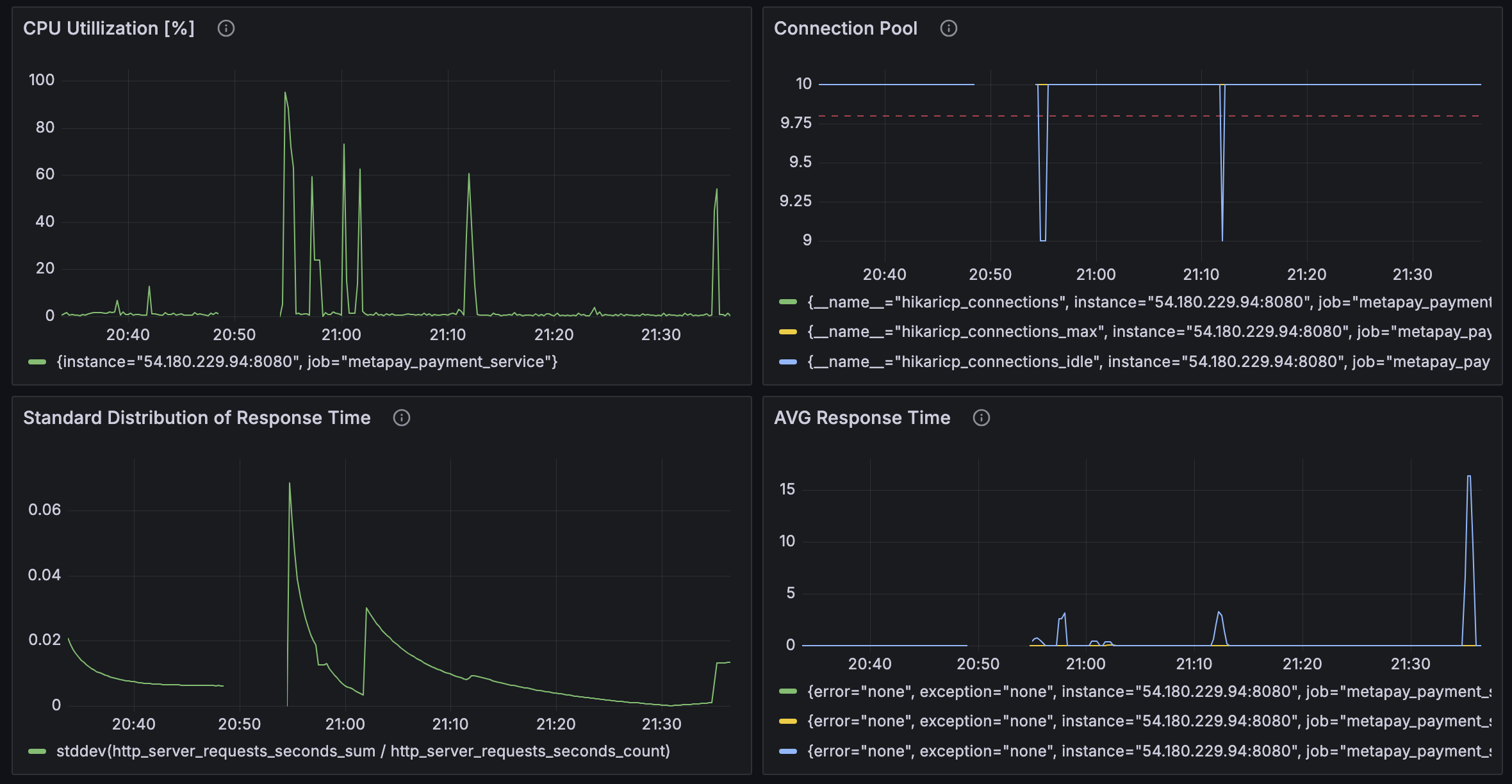
Vuser 1000명도 시도해봤는데, 1000명은 테스트를 완수할 수 없었다.
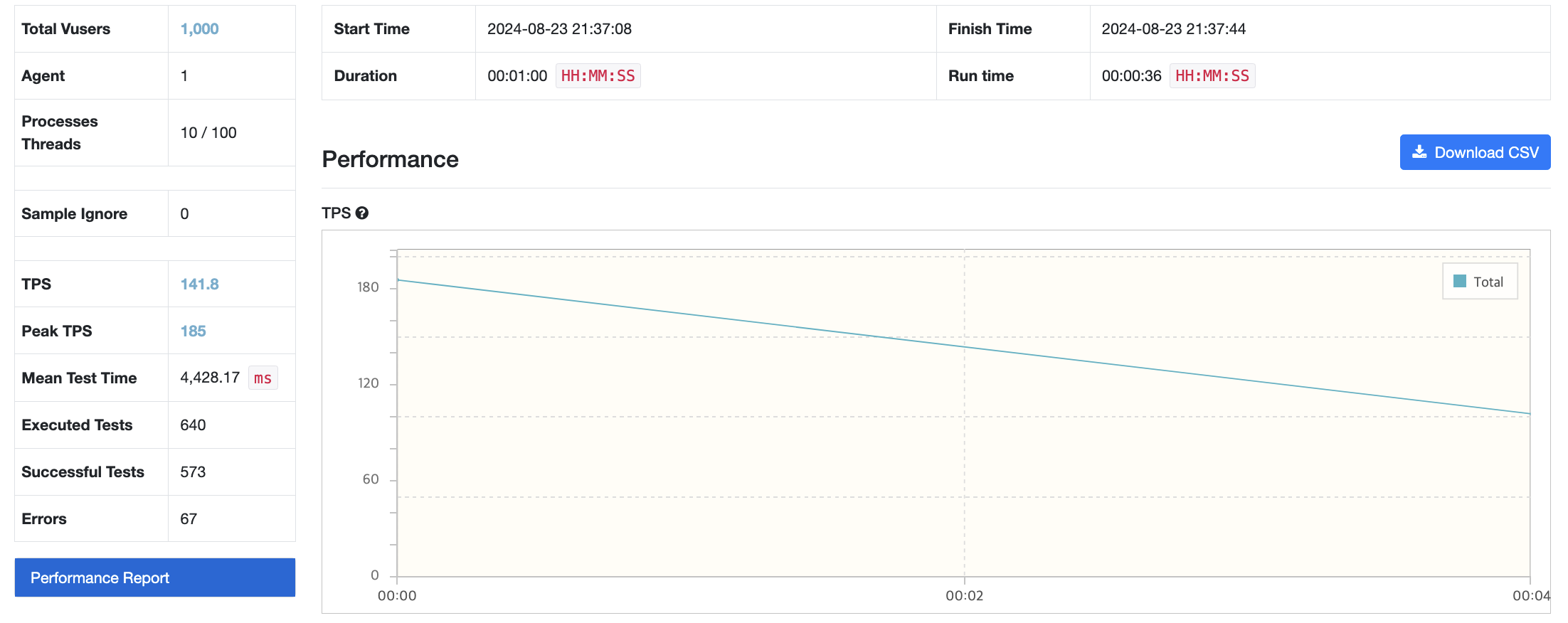
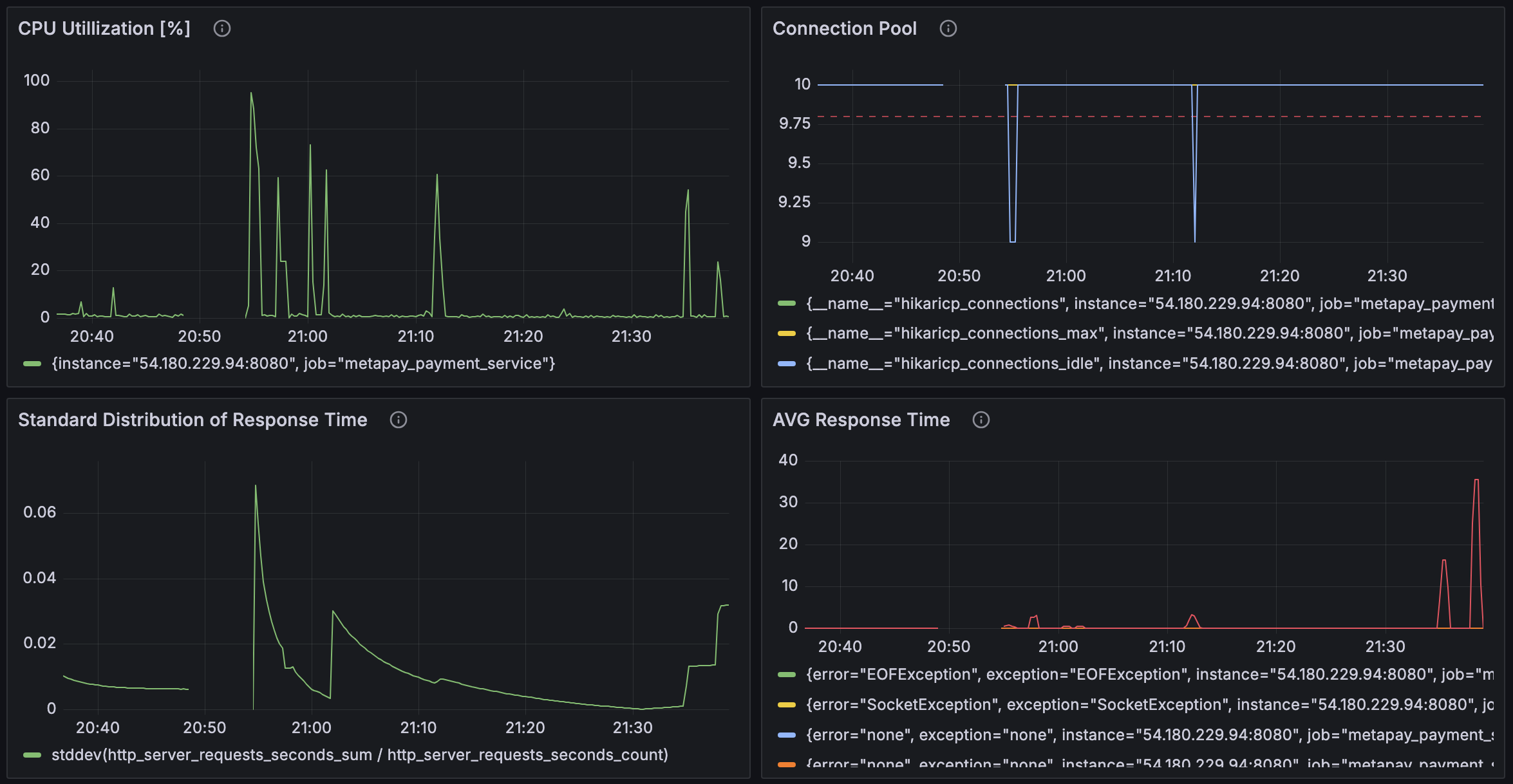

다시 Vuser 500으로 조정했더니, 이번에는 성공했다.
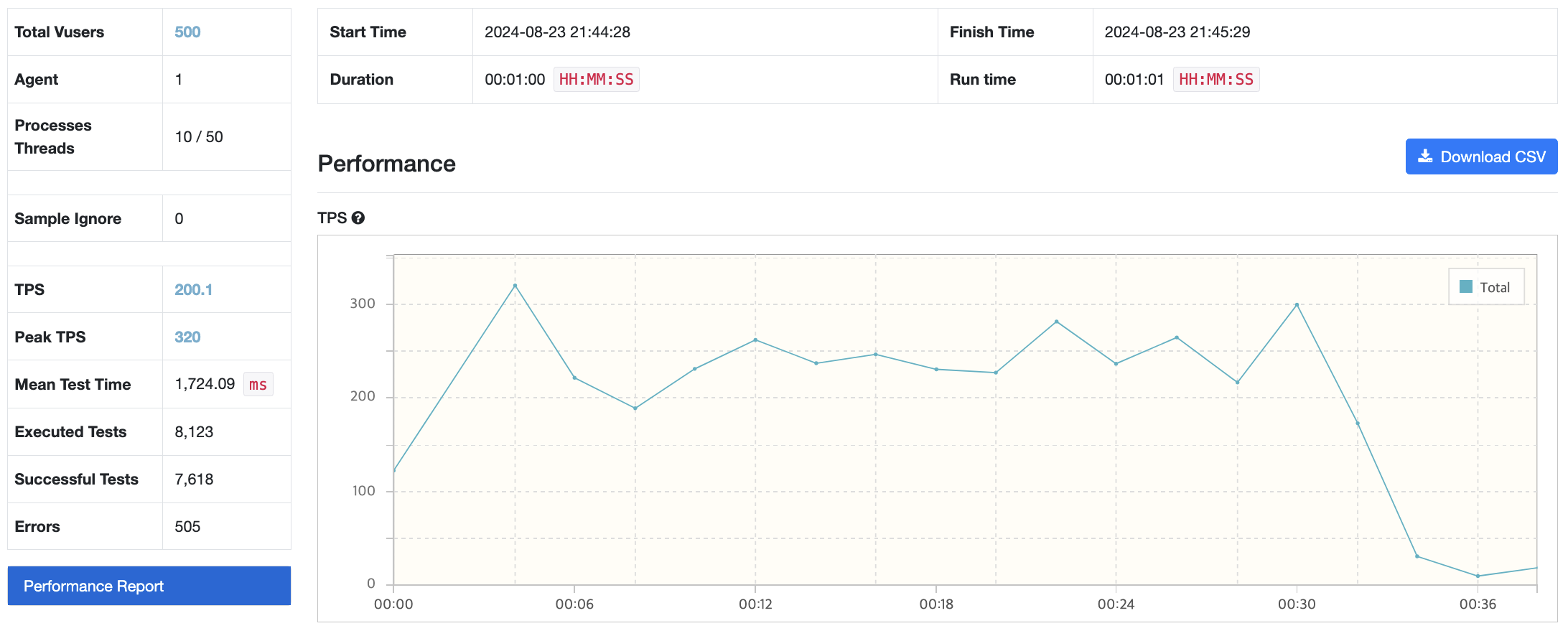
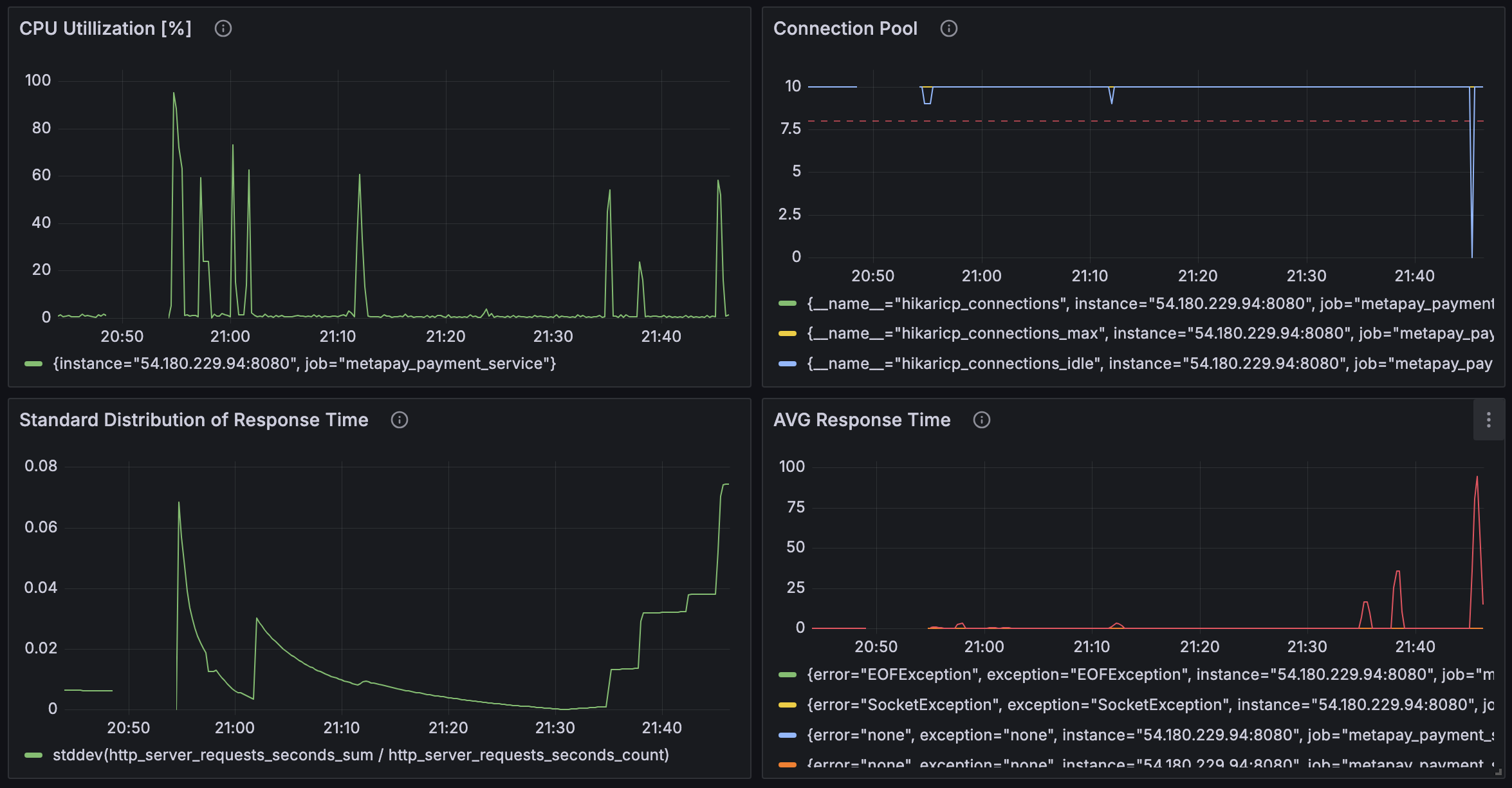



결론
Agent는 높은 부하를 발생시키기 위해서 많은 리소스를 필요로 하는 요소이다. 따라서 Agent가 테스트 하고자 하는 서비스와 같은 서버에 존재하면 Agent가 사용하는 리소스로 인해서 Service와 심각한 자원 경쟁을 벌이게 되고, 실제 Service가 리소스를 어떻게 사용했는지 알 수가 없다. 따라서 Agent와 Service는 반드시 별도의 넉넉한 리소스를 갖춘 곳으로 분리시켜 둬야 한다.
'Projects > MetaPay' 카테고리의 다른 글
| TIssue | EC2에 로드밸런서 도입했는데 신호가 Nginx에 도달도 안한다 (0) | 2024.08.25 |
|---|---|
| TIssue | AWS EC2 작동중인데 연결 안되는 이슈 (Feat. 연결 추적 테이블 nf_conntrack table이 가득참) (0) | 2024.08.25 |
| nGrinder | 성능 테스트 결과 - Dynamic UserId Case - 서버 과부하 (0) | 2024.08.20 |
| nGrinder | 성능 테스트 결과 - Simple Case (0) | 2024.08.18 |
| nGrinder | 동시성 시나리오 만들기 (0) | 2024.08.17 |



